KNN & KMeans
Project Summary
This project evaluates the fundamental mechanics of unsupervised and supervised learning through five comprehensive questions. It covers the manual and programmatic execution of K-Means clustering, Hierarchical dendrogram construction, PCA variance analysis, and the optimization of K-Nearest Neighbors (KNN) through various cross-validation techniques.
Technical Design Elements
Clustering Logic: Manual iteration of K-Means to understand centroid convergence and SciPy-based hierarchical clustering for dendrogram visualization.
Data Preprocessing: Implementation of Standard Scaling to normalize features, ensuring distance-based algorithms like KNN are not biased by variable magnitudes.
Model Selection Framework: Comparative analysis using the Validation-Set approach versus K-Fold Cross-Validation to identify the most stable hyperparameters.
Performance Metrics: Utilization of Confusion Matrices, Misclassification Error Rates, and Recall to evaluate model efficacy on imbalanced datasets.
1. K-Means Clustering (Manual Iteration)
Question 1(a) & 1(b): Perform K-means clustering manually with \(K=2\) on six observations with two features: \(X_1 = \{1, 1, 6, 5, 0, 4\}\) and \(X_2 = \{4, 3, 2, 1, 4, 0\}\). Initially assign observations #1, #2, #3 to Cluster 1 and #4, #5, #6 to Cluster 2. Report centroids and assignments until convergence.
# Extract from MH6805_Required Individual Assignment_Report _KaiElijahSeah.py
import numpy as np
obs = np.array([[1, 4], [1, 3], [6, 2], [5, 1], [0, 4], [4, 0]])
clusters = np.array([1, 1, 1, 2, 2, 2]) # Initial
# Iteration 1 Centroids
c1 = obs[0:3].mean(axis=0) # (2.67, 3.00)
c2 = obs[3:6].mean(axis=0) # (3.00, 1.67)
# Distance calculation and re-assignment
def get_assignments(data, centroids):
return np.array([np.argmin([np.linalg.norm(x - c) for c in centroids]) + 1 for x in data])
new_assignments = get_assignments(obs, [c1, c2])
# Results: [1, 1, 2, 2, 1, 2] -> Obs 3 moved to C2, Obs 5 moved to C1Answer:
Iteration 1: Initial Centroids are \(C1=(2.67, 3.00)\) and \(C2=(3.00, 1.67)\). Assignments: Cluster 1 {1, 2, 3}, Cluster 2 {4, 5, 6}.
Iteration 2: New Centroids are \(C1=(0.67, 3.67)\) and \(C2=(5.00, 1.00)\). Assignments: Cluster 1 {1, 2, 5}, Cluster 2 {3, 4, 6}.
Convergence: In Iteration 3, the assignments remain unchanged ({1, 2, 5} and {3, 4, 6}), signaling algorithmic convergence.
2. Hierarchical Clustering
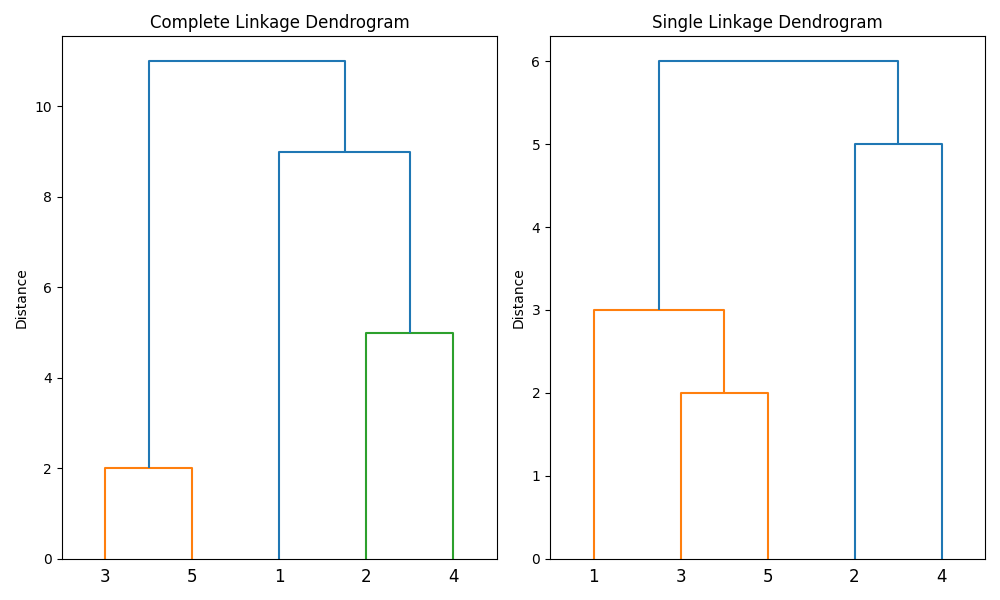
Question 2(a) & 2(b): Based on the provided similarity matrix for five observations, sketch the dendrogram and describe the clustering splits.
# Extract from MH6805_Required Individual Assignment_Report _KaiElijahSeah.py
from scipy.cluster.hierarchy import linkage, dendrogram
from scipy.spatial.distance import squareform
matrix = np.array([[0, 9, 3, 6, 11], [9, 0, 7, 5, 10], [3, 7, 0, 9, 2], [6, 5, 9, 0, 8], [11, 10, 2, 8, 0]])
Z = linkage(squareform(matrix), method='single')
dendrogram(Z, labels=[1, 2, 3, 4, 5])Answer:
Merge 1: Observations 3 and 5 merge first (Distance = 2).
Merge 2: Observation 1 joins {3, 5} (Distance = 3).
Merge 3: Observations 2 and 4 merge (Distance = 5).
Result: If the dendrogram is cut to yield two clusters, we obtain \(\{1, 3, 5\}\) and \(\{2, 4\}\).
3. Principal Component Analysis (PCA) Logic
Question 3: Describe how PCA would be applied to a dataset where \(X_1\) and \(X_2\) have different variances.
Answer:
Variance Check: If \(Var(X_1) = 0.301\) and \(Var(X_2) = 1.157\), the features are on different scales.
Requirement: Scaling is mandatory.
Reasoning: PCA is a variance-maximizing exercise. Without scaling, the first principal component would be artificially forced to follow \(X_2\) because its absolute variance is higher, regardless of the actual information density.
4. KNN: Scaling and Classification
Question 4(a), 4(b) & 4(c): Evaluate variances for the Caravan dataset, scale the data, and apply KNN (\(K=3\)).
# Extract from MH6805_Required Individual Assignment_Report _KaiElijahSeah.py
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
scaler = StandardScaler()
X_train_s = scaler.fit_transform(X_train)
X_test_s = scaler.transform(X_test)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train_s, y_train)
error_rate = 1 - knn.score(X_test_s, y_test)Answer:
Variances: Initial variances range from 0.16 to over 1000, confirming that scaling is necessary to prevent large-magnitude variables from dominating Euclidean distance.
Performance: At \(K=3\), the misclassification error is 0.0760.
Classification Table: Only 3 out of 29 “Purchase” observations were correctly identified, indicating high accuracy but very low recall for the target class.
5. Hyperparameter Tuning (Optimal K)
Question 5(d), 5(e) & 5(f): Determine the optimal \(K \in \{3, ..., 20\}\) using the Validation-Set approach (with two different seeds) and 5-Fold Cross-Validation.
# Extract from MH6805_Required Individual Assignment_Report _KaiElijahSeah.py
from sklearn.model_selection import cross_val_score
# 5-Fold CV Implementation
cv_errors = []
for k in range(3, 21):
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X_train_s, y_train, cv=5, scoring='accuracy')
cv_errors.append(1 - scores.mean())
optimal_k_cv = range(3, 21)[np.argmin(cv_errors)] # K=8Answer:
Seed 23847 (Validation): Optimal \(K = 9\), Error = 0.0594.
Seed 23846 (Validation): Optimal \(K = 8\), Error = 0.0601.
5-Fold CV: Optimal \(K = 8\), Error = 0.0595.
Final Comparison of All Approaches
| Approach | Seed | Optimal K | Min Error | Stability Analysis |
|---|---|---|---|---|
| Validation Set 1 | 23847 | 9 | 0.0594 | High variance; result changes with seed. |
| Validation Set 2 | 23846 | 8 | 0.0601 | Vulnerable to specific data splits. |
| 5-Fold CV | 23847 | 8 | 0.0595 | Most robust; averages over 5 different splits. |
Summary
The assignment demonstrates that while distance-based models like KNN and K-Means are mathematically intuitive, their success relies heavily on Standard Scaling. Furthermore, hyperparameter tuning via a single Validation Set is unreliable due to its sensitivity to random data splits. K-Fold Cross-Validation is the superior method for selecting the optimal \(K\), as it provides a more stable and generalized estimate of the test error.
Contribution: This assignment is completed by Kai Elijah Seah. The code for the K-Means manual iteration, hierarchical clustering, PCA variance analysis, and KNN classification is extracted from MH6805_Required Individual Assignment_Report _KaiElijahSeah.py. The report includes detailed explanations of the algorithms, results, and insights derived from the analysis.